¶机器学习评价指标-精确率和召回率(precision-recall)
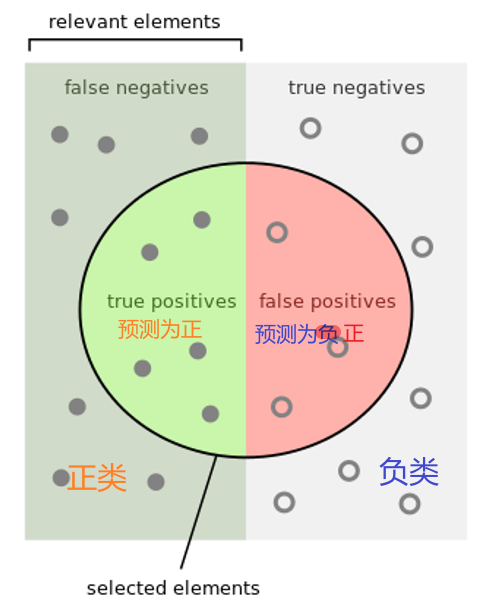
信息检索中Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了,衡量的检索系统的查全率。
- True Positive(真正, TP):将正类预测为正类数.
- True Negative(真负 , TN):将负类预测为负类数.
- False Positive(假正, FP):将负类预测为正类数 → 误报 (Type I error).
- False Negative(假负 , FN):将正类预测为负类数 → 漏报 (Type II error).