以泰坦尼克号的数据为例介绍一下前期对数据的基础操作。
引入库
1 | import csv as csv |
读取文件
1 | train = pd.read_csv(r"文件目录") |
此时数据的样式是:

数据概览
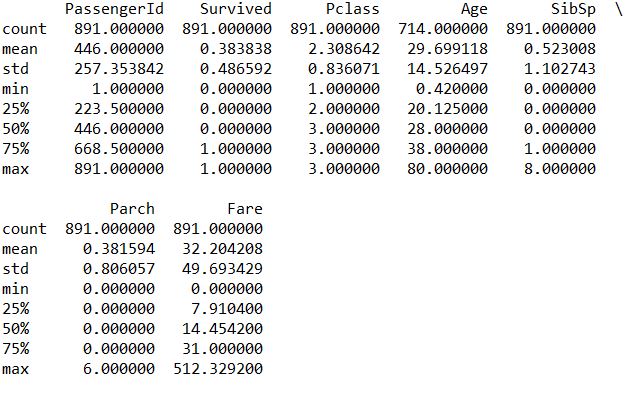
- describe 显示整体数据常见属性
1 | print(train.describe()) |
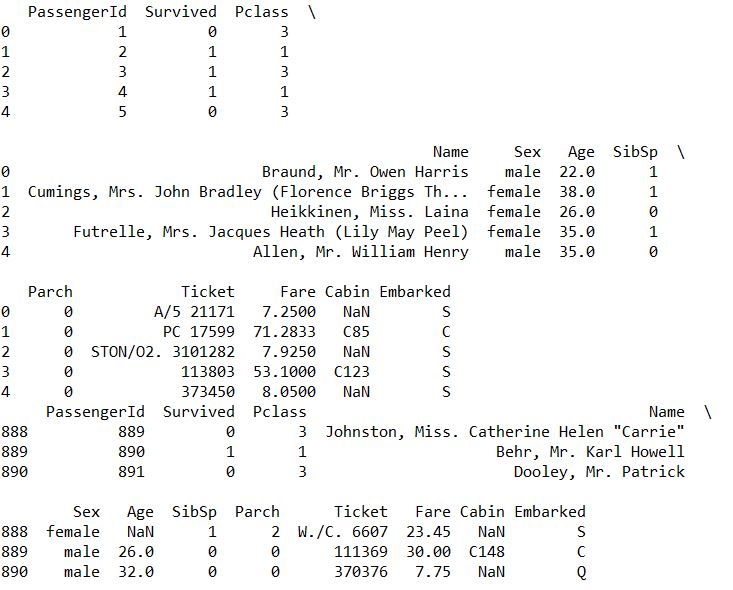
- head tail 显示首尾一些数据
1 | print(train.head(5)) |
- index:索引,默认自建整型索引;columns:列;values:数据数值
1 | print(train.index) |
数据操作
- T:数据的转置
1 | print(train.T) |

- sort:可以按索引或者值进行排序,axis选择维度(行还是列),ascending选择升序或者降序,Nan永远排在最后,无论升序降序
1 | print(train.sort_index(axis=0,ascending=True)) |
数据选择
- 按照标签选择,选择列,行切片
1 | print(train['Age']) |
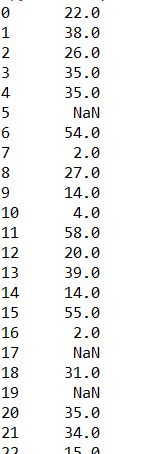
- 利用loc自由选择某些行某些列,可以用at替代
1 | print(train.loc[train.index[4:6]]) |
- 利用iloc按照位置进行选择
1 | print(train.iloc[5]) |
- 布尔选择
1 | print( train[ (train['Age']>40) & (train['Age']<50) ] ) |

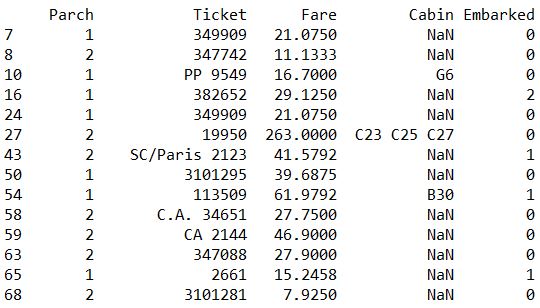

缺失值处理
- 利用reindex选择部分数据进行拷贝,并进行缺失值处理。一些函数会自动过滤掉缺失值,比如mean()
1 | train1=train.reindex(index=train.index[0:5],columns=['PassengerId']+['Age']+['Sex'])#选择前5行,只取选定的三列 |
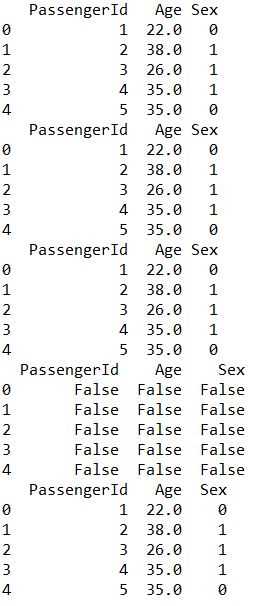
应用函数
- 可以自己写函数并应用到数据的行或者列,通过axis参数选择行列
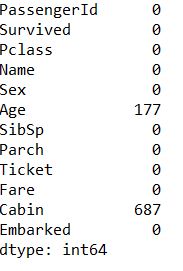
1 | #写函数统计包含nan值的行数 |
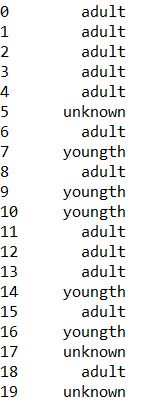
1 | #写函数对年龄列进行分类 |
数据透视表
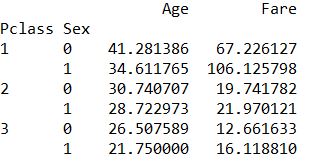
- 自选分类和值进行数据透视,比如按照pclass和sex分类,统计age和fare的平均值
1 | print(train.pivot_table(index=["Pclass","Sex"], values=["Age", "Fare"], aggfunc=np.mean)) |
数据合并
-
数据合并的一些操作,待补全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import pandas as pd
data1 = pd.DataFrame({'level':['a','b','c','d'],
'numeber':[1,3,5,7]})
data2=pd.DataFrame({'level':['a','b','c','e'],
'numeber':[2,3,6,10]})
print("merge:\n",pd.merge(data1,data2),"\n")
data3 = pd.DataFrame({'level1':['a','b','c','d'],
'numeber1':[1,3,5,7]})
data4 = pd.DataFrame({'level2':['a','b','c','e'],
'numeber2':[2,3,6,10]})
print("merge with left_on,right_on: \n",pd.merge(data3,data4,left_on='level1',right_on='level2'),"\n")
print("concat: \n",pd.concat([data1,data2]),"\n")
data3 = pd.DataFrame({'level':['a','b','c','d'],
'numeber1':[1,3,5,np.nan]})
data4=pd.DataFrame({'level':['a','b','c','e'],
'numeber2':[2,np.nan,6,10]})
print("combine: \n",data3.combine_first(data4),"\n")
