- 以简单的Iris数据集做测试,实现了K-means++聚类算法,并与sklearn中自带的KNN算法进行比较
- 标题本来是K-Means&KNN,把&改成了和,因为标题中出现特殊符号&会导致我的sitemap生成错误…

简介
- K-Means是简单的基于划分的聚类方法,要解决的问题是,现在有n个样本(点集X),将他们的特征向量投射到高维空间中,根据空间分布可以大致划分成几个子空间,每个子空间中的点属于同一类,现在需要计算出每个点所在的类,大致思想就是随机选择k个点(中心点集C)作为中心点,其余的点自己站队:离k个中心点里哪个点最近就站那个点的队,即和那个中心点划分到同一类中,这样就能形成k个类,重复上过程,期间引入一个损失评估,比如以各个类中的点到这个类中心点距离的和作为评估指标,当指标小于某一程度或者指标变化小于某一程度就停止重复
- KNN则比较简单粗暴,其思想类似于民主投票。KNN不训练数据,选定一个值K,对于每一个需要预测的向量,在已知类别的数据集中找到与这个向量最近的K,这K个点中拥有最多点个数的类别就是预测类别,即让离某个点最近的K个点投票决定这个点的类别,哪个类别的点票数多就是哪个类别
K-means++
- k-means++在k-means上优化了初始k个点的选择。原始算法是随机取k个点,显然这样随机不确定性太大,比较好的k个点的选择方案应该是他们离彼此尽量远,但不能太远。尽量远,就能尽可能贴近最终理想中心点分布;不能太远,是为了防止将一些错误点孤立点作为中心点
- 算法上的实现是先随机从X集中取第一个中心点,之后反复以下过程取中心点
- 计算每个点$c_i$到已经选出的中心点$k_1,k_2…$的距离,选取最小的一个距离作为$c_i$的距离,这个距离的意义即$c_i$作为下一个中心点时离其他中心点至少有多远
- 将$c_1,c_2,c_3…$的距离归一化,并排成一条线
- 这条线长度为1,分成了许多段,每一段的长度就代表了这一段所代表的点的距离在归一化中所占的比例,距离越大,比例越大
- 在(0,1)之间随机取一个数,这个数所在的段区间所代表的点就是下一个中心点,将其加入中心点集C,接着重复找下一个中心点
- 可以看出,如果距离够远,在线上被随机抽到的可能越大,符合我们的需求
K-Means代码实现
¶数据检视
- Iris是鸢尾花分类数据集,150个样本,均匀分成3类,每一个样本有4个属性
![i0otpV.jpg]()
¶初始化数据
- 初始化数据
1 | def init(): |
¶k-means++初始化k个点
- D2是每个点的距离(即之前定义的里其他中心点至少有多远)
- probs归一化
- cumprobs将归一化的概率累加,排列成一条线
1 | def initk(X_train, k): |
¶损失评估
- 在这里用每个类内点到中心点距离平方和的总和作为损失评估
1 | def evaluate(C, X_train, y_predict): |
¶聚类
- 初始化k个中心点后,所有的点就可以分类
- 重新在每个类中取中心点,在这里取一个类中所有点坐标平均作为中心点坐标
1 | def cluster(C, X_train, y_predict, k): |
¶主函数
- 计算损失,更新k个中心点,再站队(聚类)一次
- 重复,直到损失变化小于10%
- 每次迭代显示新旧损失,显示损失变化
- 最后输出分类结果
1 | def main(): |
KNN代码
- 直接使用了sklearn中的KNeighborsClassifier
1 | from sklearn.datasets import load_iris |
预测结果
-
指标说明
对于二分类,四种情况的总数:对的预测成对的TP;对的预测成错的FN;错的预测成对的FP;错的预测成错的TN
$$
精确率:P=\frac{TP}{TP+FP} \
召回率:R=\frac{TP}{TP+FN} \
1F值:\frac {2}{F_1}=\frac1P+\frac1R \
$$ -
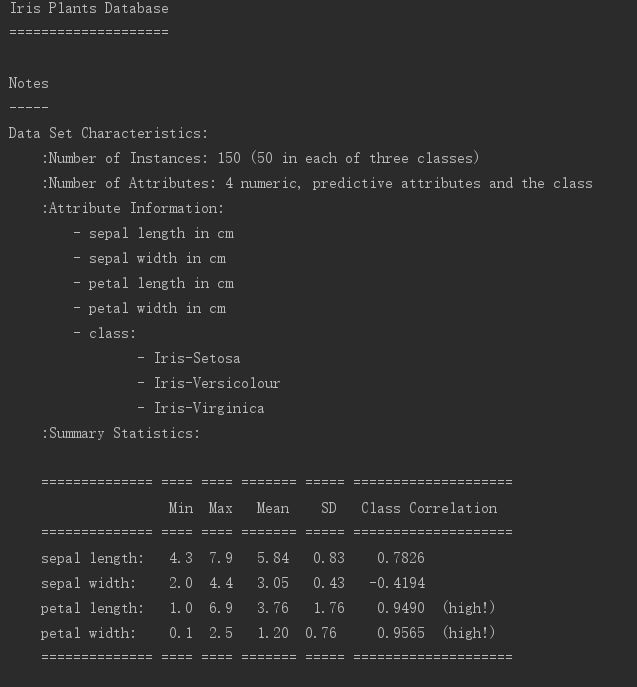
K-Means程序输出
预测正确率:88.39%
平均精确率:89%
召回率:0.88
F1指标:0.88
![i0o1Ts.jpg]()
-
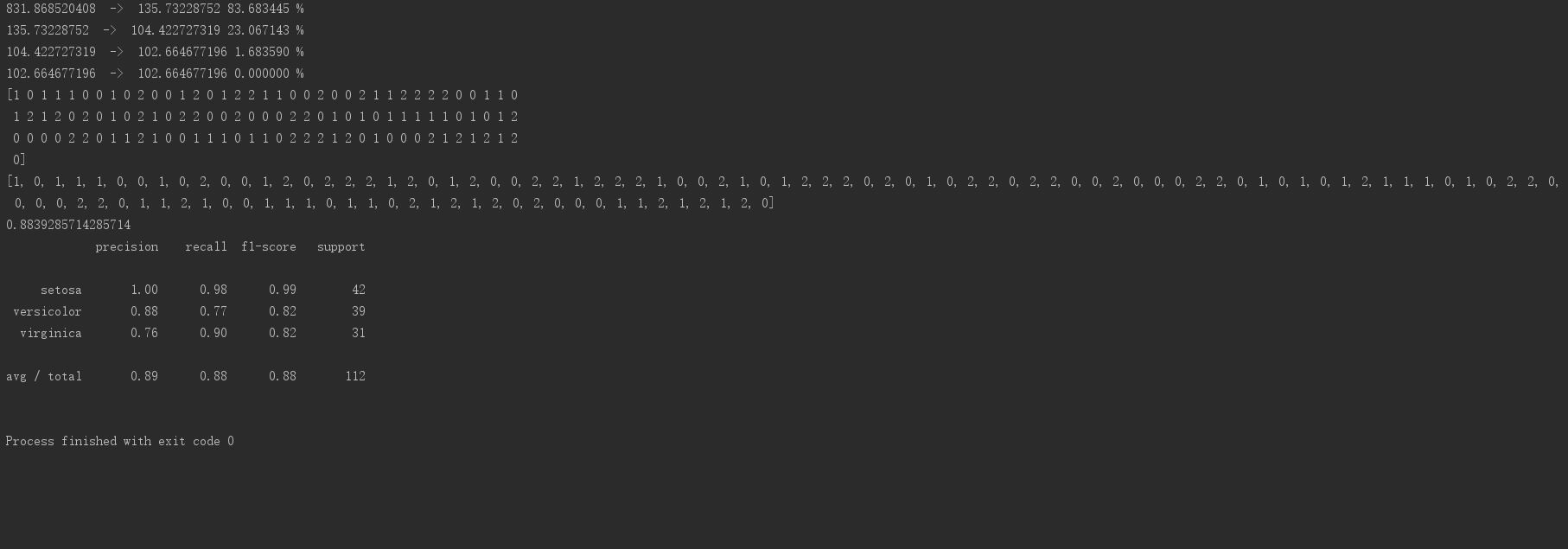
KNN程序输出
预测正确率:71.05%
平均精确率:86%
召回率:0.71
F1指标:0.70
![i0oKOg.jpg]()
-
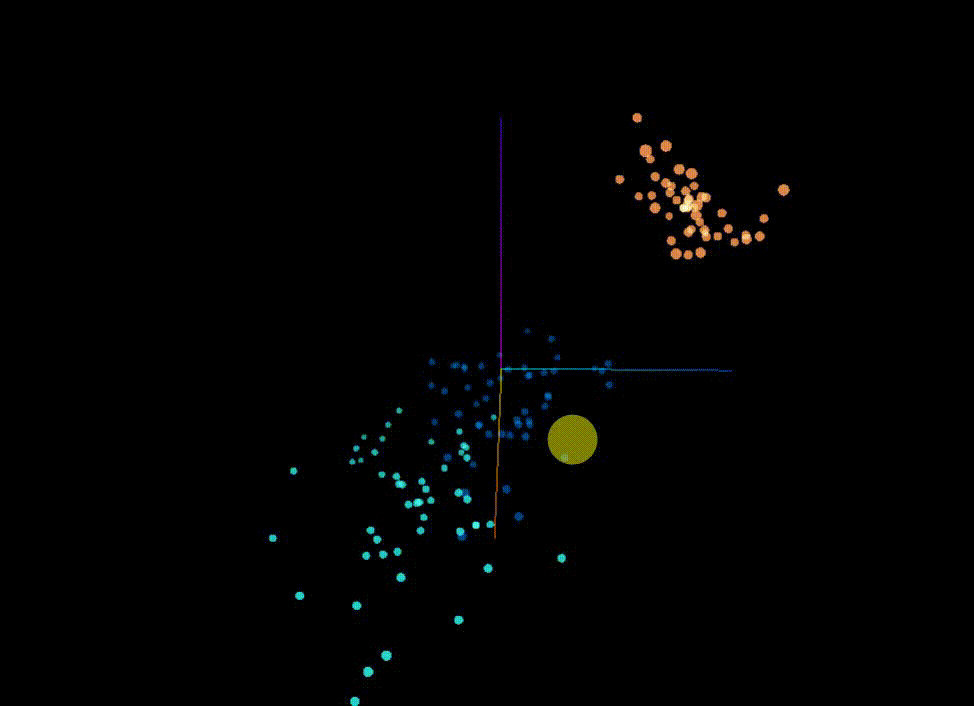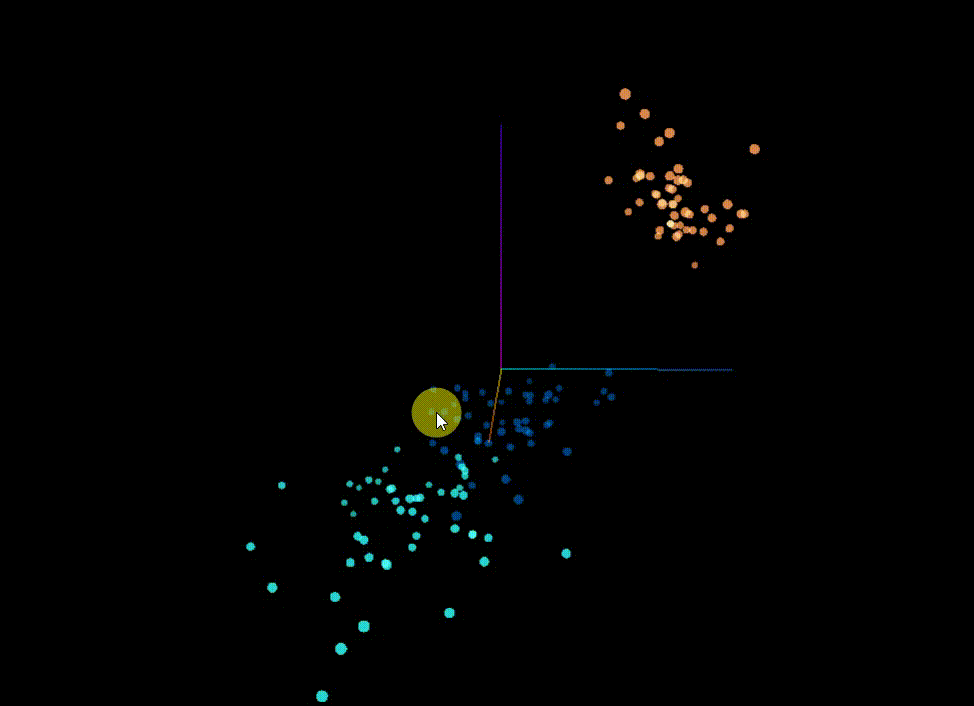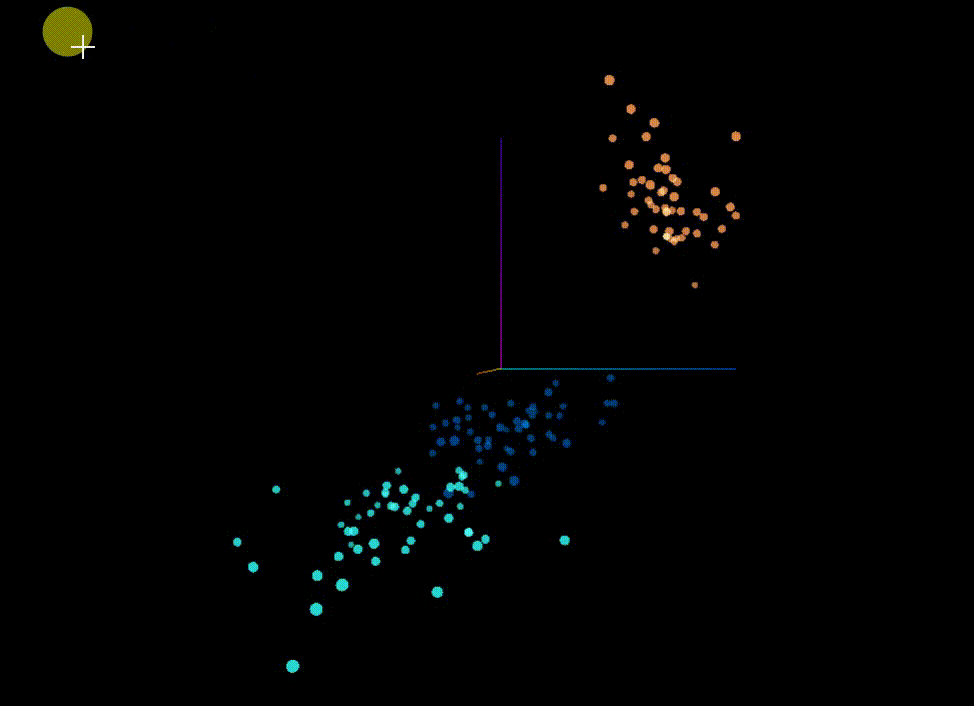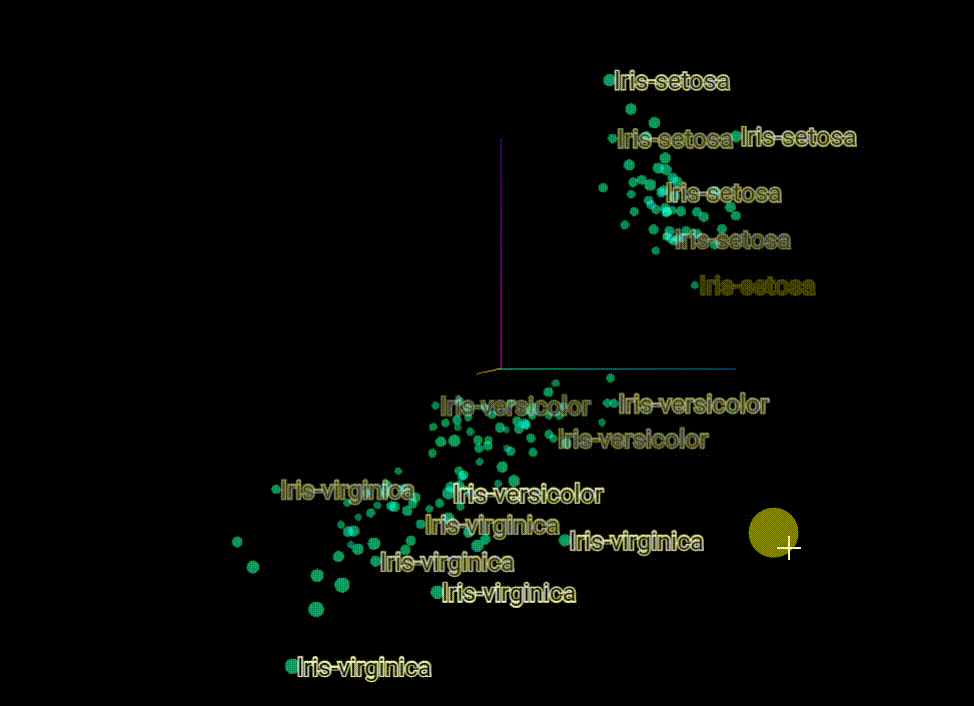
原始分类
可以看到这个数据集本身在空间上就比较方便聚类划分
![i0oQmQ.gif]()
-
预测分类
![i0o8kn.gif]()

改进
¶未知k的情况
- 以上是我们已知鸢尾花会分成3类,加入我们不知道有几类呢?毕竟k-means是无监督学习,可以在无标签的情况下计算,自然标签的个数我们也极有可能不知道,那么如何确定k?
- 一种方式是canopy算法
- 待补充
¶空类的处理
- 待补充
¶不同距离计算方式
- 待补充