机器学习算法的好坏不仅取决于参数,而且很大程度上取决于各种超参数。
¶有关超参寻优有很多比较经典的方法:
-
随机搜索(Random search)
-
网格搜索(Grid search)
-
贝叶斯优化(Bayesian optimization)
-
强化学习(Reinforcement learning)
-
进化算法(Evoluyionary Algorithm)
这些方法统称为Hyperparameter optimization (HO),像Auto-sklearn和Auto-WEKA都是比较有名的HO框架。
对于深度学习而言,超参数主要分为两类:
- 一类是训练参数:如learning rate,batch size,weight decay等等
- 另一类是网络结构的参数:比如每层的filters,filter size,stride等
前者的自动调优就是HO的范畴,但是后者的自动调优一般称为网络架构搜索(Network Architecture Search, NAS)
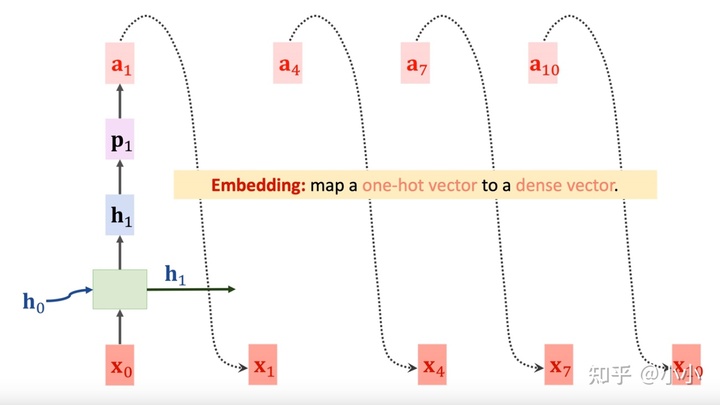
¶NAS via RNN+ RL
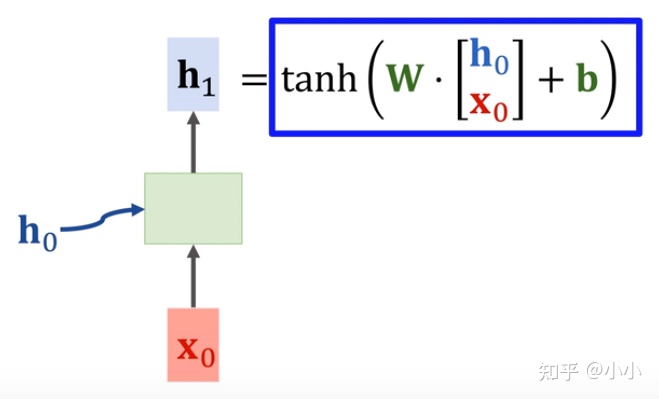
- RNN的一个cell,将输入线性映射之后,使用双曲正切函数进行非线性激活
- 然后通过一个dense层+softmax层将激活结果进行概率化处理
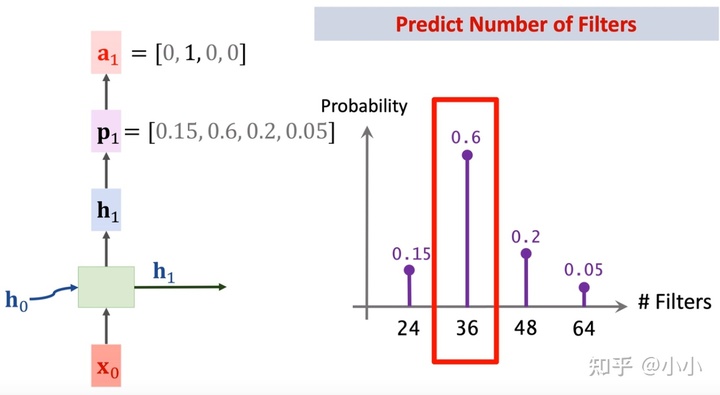
-
然后将输出结果进行Embedding处理,作为下一时刻的输入,
![4aA6b9.jpg]()