¶NLP中的语言表征(representations)
与CV一样,NLP也需要有效的表征(representation)去完成下游的任务,这些representation在NLP的叫法很多,比如embeddings,distributed representation,但本质都是低维的(low-dimensional)dense的vectors。
一个好的语言表征,应该能包含着潜在的语法,常识,隐含着句法,语义等特征。与CV不一样的是,CV一般用一个vector去表示一张image,而NLP的一个vector则表示一个word,要么是non-contextual,要么是contextual。
那这些表征怎么学习到的呢?早期是通过监督学习,但是有人工标注的数据集毕竟有限,如果模型太过复杂,容易过拟合,泛化不好等等。但是我们有海量的无标注数据,能不能直接拿来训练,来学习通用的语言表征(universal language representation)?这就引出来预训练模型pre-trained models (PTMs),
一般来说,还是得通过无监督学习或者自监督学习,而表征呢,就是这些PTMs的输出而已。这里又进一步把word embeddings分为:
- Non-contextual:学习好的词向量word embeddings,一般shallow,计算高效,如Skip-Gram,GloVe,虽然能捕获词的语义信息,但是context-free,不能捕获high-level的上下文信息,也就是传统的word2vec,一个词学习到一个vector,到下游的NLP任务,该vector固定不变,是静态的。
- Contextual:学习带有上下文的contextual word embeddings,比如,CoVe,ELMo,OpenAI GPT和BERT,词的表征可以根据上下的语境而动态改变。
¶Non-contextual embeddings
定一个文本序列 $x_1,x_2,…,x^T$ ,每一个token $x^T$都属于vocabulary $V$,通过一个lookup table $E\in R^{D_e \times |V|}$ 可以得到对应的embedding
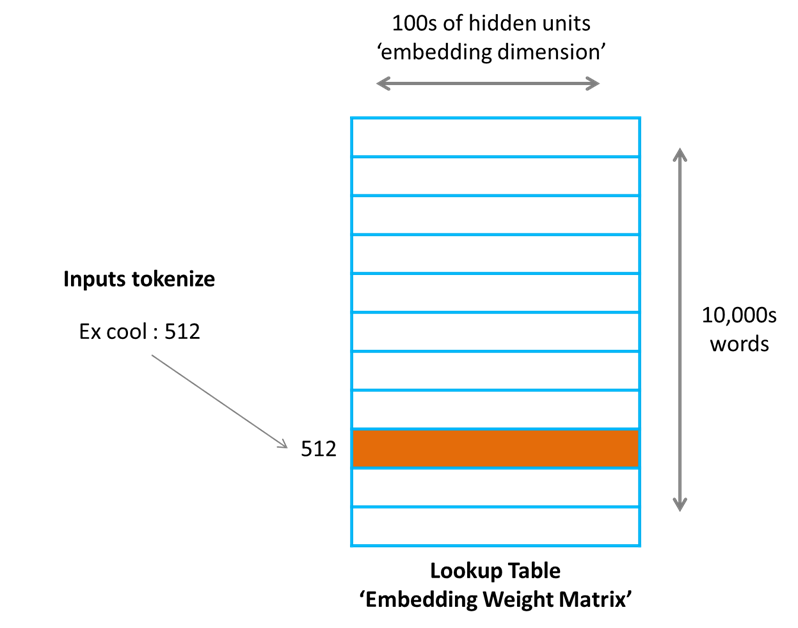
换个角度看,查表过程,也其实就是把one-hot的vector做矩阵的乘法运算:
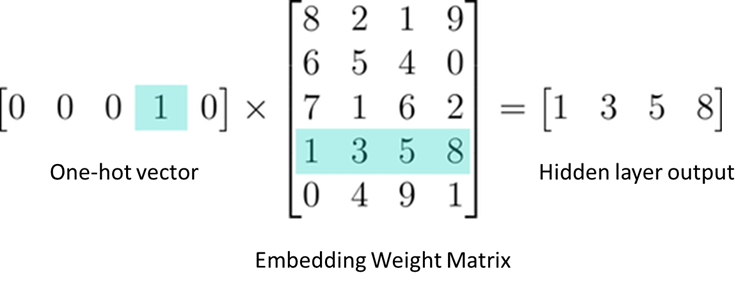
这些word embedding是静态不变的,这种word embedding可以捕获到单词中语法和语义的关系,比如 vec(“China”) - vec(“Beijing”) ≈ vec(“Japan”) - vec(“Tokyo”)。再比如vec(“Germany”) + vec(“capital”) 接近于vec(“Berlin”)。
¶常用的off-the-shelf word embedding:
- 谷歌的Word2Vec(2013),在300万个单词的Google News data 上训练,维度是300维,采用的是skip-gram和negative sampling的方法。
- Stanford的Glove,第一个版本发布于2014年,可以提供25-300维不等,用的是word-to-word的co-occurrence的方法,如果两个单词共同出现很多次,说明它们有一定的语言或语义的相似性。
- Facebook的fastText,第一个版本发布于2017年,维度也是300维,可以在sentence classification实现很好的性能,原因是利用了character level的表征。每个单词除了单词本身,还表示为n-grams的bag of characters。