¶BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
¶摘要
文章提出一个预训练sequence-to-sequence的去噪自编码器:BART。BART的训练主要由2个步骤组成:
- 使用任意噪声函数破坏文本
- 模型学习重建原始文本。
¶BERT and GPT
BART 使用基于 Transformer 的标准神经机器翻译架构,可视为BERT(双向编码器)、GPT(从左至右的解码器)等近期出现的预训练模型的泛化形式。文中评估了多种噪声方法,最终发现通过随机打乱原始句子的顺序,再使用首创的新型文本填充方法(即用单个 mask token 替换文本片段,换句话说不管是被mask掉多少个token,都只用一个特定的mask token表示该位置有token被遮蔽了)能够获取最优性能。
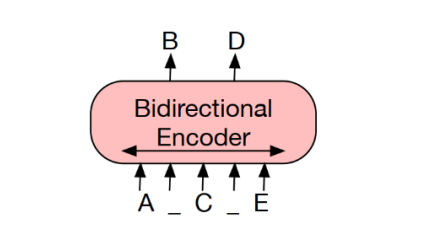
¶BERT:用掩码替换随机 token,双向编码文档
由于缺失 token 被单独预测,因此 BERT 较难用于生成任务。
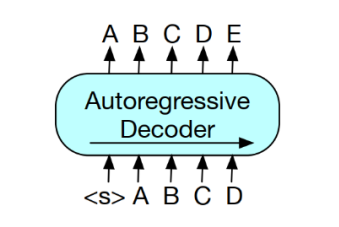
¶GPT:使用自回归方式预测 token,
这意味着GPT可用于生成任务。但是,该模型仅基于左侧上下文预测单词,无法学习双向交互
¶BART
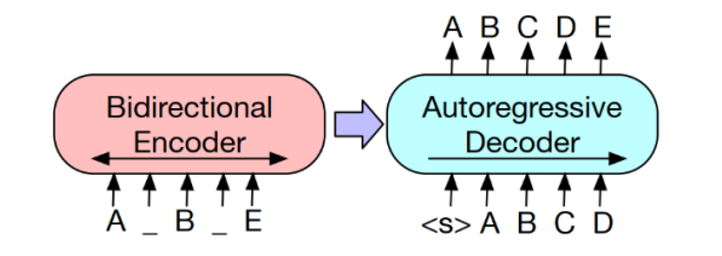
编码器输入与解码器输出无需对齐,即允许任意噪声变换。使用掩码符号替换文本段,从而破坏文本。使用双向模型编码被破坏的文本(左),然后使用自回归解码器计算原始文档的似然(右)。
至于微调,未被破坏的文档是编码器和解码器的输入,研究者使用来自解码器最终隐藏状态的表征。